Open source release! Generalized linear modeling with glum and tabmat.
I’m super excited to announce the release of glum and tabmat. These are the first two open source projects that QuantCo has released! Hopefully there will be many more. glum is a efficient and featureful Python-first library for generalized linear model (GLM) estimation built with an sklearn-style API. We focused a ton on correctness, performance and satisfying a wide range of feature requirements.
While working on this project, my coworkers and I heard repeatedly from folks on other data science or economics teams that they either struggled with the same GLM software problems we had or they had built their own internal GLM tool similar to glum. I’m really happy to be able to help rectify this situation and release something that the whole community can use.
We started working on glum in March 2020 and it’s been in heavy use within QuantCo since July 2020. During that same timeframe, tabmat grew out of our efforts to make glum as fast as possible when we realized that a key performance issue was efficiently handling a mix of dense, sparse and categorical subcomponents. You can read a lot more about the story behind glum.
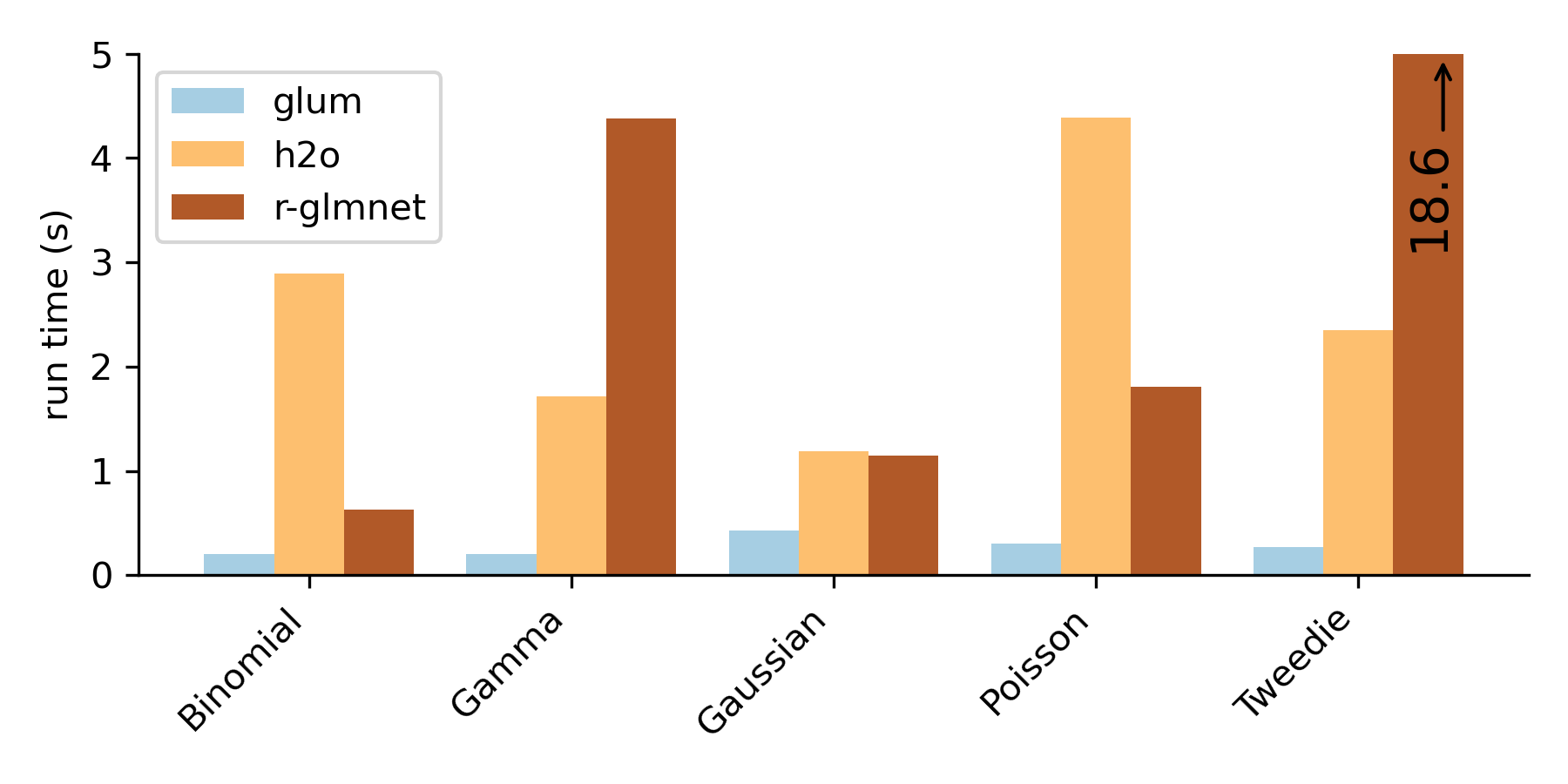
glum is at least as feature-complete as glmnet and h2o, two of the most popular existing GLM tools. On top of the capabilities that you know and love from those packages like elastic net regularization, regularization paths and automatic cross validation, we have some additional features that might get people excited:
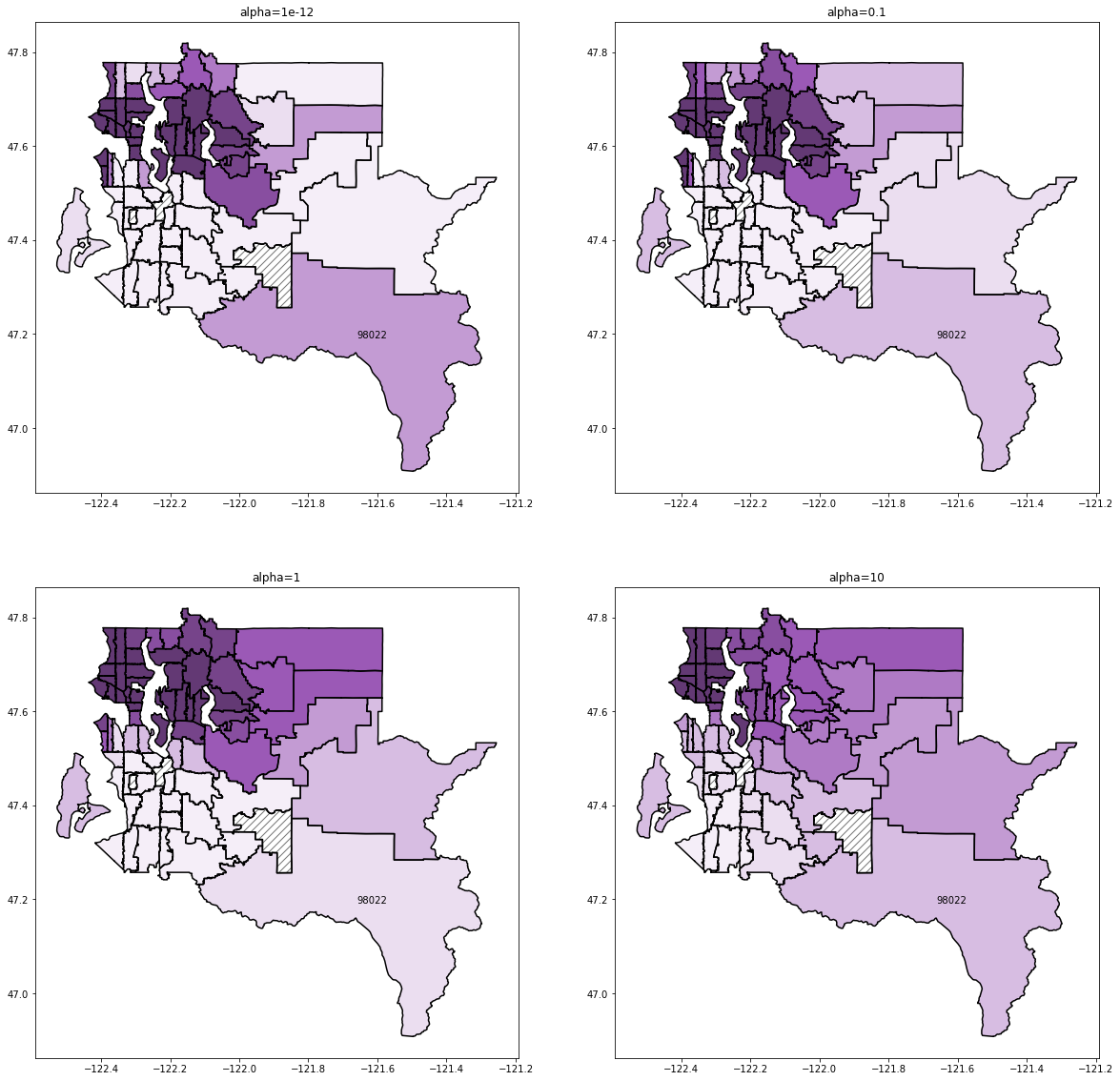
- Variable L1 and elastic net penalties and variable matrix-valued Tikhonov matrices. This means you can choose how much to regularize each parameter and, in the L2-case, each pair of parameters. We’ve used this to do things like spatial smoothing for zipcode fixed effects. Check out this example figure
- Linear inequality constraints on parameters. We’ve faced several situations in insurance pricing where we need to enforce constraints on a linear combination of parameters. This is not a commonly available feature because it makes
- Handling extremely wide categorical problems. Because
tabmathandles categorical matrices very efficiently, we can smoothly work with problems that have hundreds of thousands or millions of indicator variables. - Arbitrary distributions and link functions. We work with Tweedie and Gamma distributions a lot in our insurance work. Lack of support for these distributions motivated us to make sure that users can extend
glumto work with whatever distributional assumptions they want so long as the choices still fit within the framework of a GLM.
If you’re interested in using glum, check out the getting started guide and the tutorials!
Different levels of smoothing between adjacent zip-codes when predicting home prices. There’s a full tutorial showing how to do this!